
Le mouvement d’ouverture des données de recherche sur la scène européenne ou africaine semble entraîner une ruée des chercheurs vers les entrepôts de données. Dans ce contexte, des facteurs comme l’obsolescence des formats de fichier, le développement des nouvelles pratiques informationnelles, c’est-à-dire la manière dont l’on s’approprie un dispositif d’information donné, font en sorte que l’analyse qui précède la mise en place ou le choix d’un entrepôt de données de recherche paraît complexe. Car le chercheur qui souhaite stocker les données de recherche devra cerner les usages d’un dispositif par rapport à la donnée qu’il souhaite valoriser. Mais aussi identifier la structure de l’outil choisi pour en déterminer les spécificités. Dans cet article, il s’agira pour nous de cerner la notion d’entrepôt de données ; et du comment les choisir pour l’hébergement des données de recherche. Ensuite nous dresserons une analyse comparée de quelques entrepôts de données de la scène européenne et africaine.
Tout savoir sur les entrepôts de données
Pourquoi un entrepôt ?
Dans le monde de la recherche scientifique, il est important de collaborer et de faire connaître les travaux de recherche. Cela atteste de l’avancée de la recherche et de la crédibilité du chercheur (autorité scientifique). C’est pourquoi les entrepôts de données sont des dispositifs web qui permettent d’identifier la structure (formats, métadonnées, contenus etc.) des données de recherche stockées par les chercheurs. De plus, ils permettent une conservation pérenne et une utilisation ultérieure des données stockées. D’après le CIRAD : « un entrepôt de données de recherche (Research Data Repository ou Data Repository) est une base de données destinée à accueillir, conserver, rendre visibles et accessibles des données de recherche »[1].
Autrement dit, il s’agit d’un réservoir susceptible de stocker diverses informations de manière structurée et dans lequel cette information peut être retrouvée.
Quelle est la structure d’un entrepôt de données ?
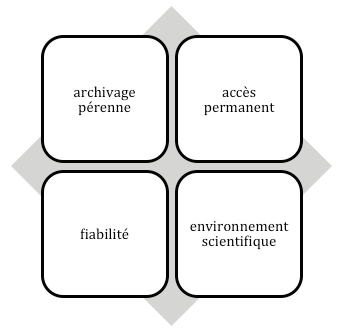
Un entrepôt de données de recherche est composé d’une structure unique qui prend en compte 4 éléments essentiels d’après Hélène Prost et Joachim Schöpfel [2] (fig. 1).
L’archivage pérenne tels que décrit par la norme (ISO 14641:2018, relative à l’Archivage électronique – Conception et exploitation d’un système informatique pour la conservation intègre de documents électroniques – Spécifications) [3] doit répondre à un ensemble d’exigences liées à la conservation du document, l’accessibilité et l’intelligibilité. En d’autre termes, les supports des données déposés doivent maintenir leurs intégrités comme au moment du dépôt par leurs auteurs, les données doivent êtres exploitables par les terminaux de lecture et d’écriture, et enfin les données doivent comporter des éléments additionnels (métadonnées) répondant à des standards de description des données (Dublin Core, KBart, Marc XML, TEI, METS etc.) qui faciliteront leur compréhension et leur exploitation par n’importe quel utilisateur ou système d’information.
{kind=link}
De plus, l’accès permanent fait référence à la disponibilité en toute circonstance des données. C’est la raison pour laquelle, chaque donnée possède un identifiant pérenne appelé DOI (Digital Object Identifier) qui permet de la différencier d’une autre donnée ayant les mêmes propriétés en termes de format, support etc. La fiabilité est la capacité pour une donnée de pouvoir être citée et vérifiée.
Et enfin l’environnement scientifique prend en compte l’idée selon laquelle chaque donnée produite a été réalisée dans le cadre d’une activité scientifique, qui appartient à un domaine de connaissance précis ayant un objet d’étude et des méthodes.
Qui sont les utilisateurs des entrepôts ?
Lorsque vient le moment de la publication ou la consultation des données de recherche, on aperçoit généralement 5 types de publics à savoir :
- Professionnels des Sciences de l’Information et de la Communication (SIC) ;
- Chercheurs ;
- Laboratoires de recherche ;
- Étudiants.
- Organisations publiques ou privées
En fonction du profil de l’utilisateur, le type d’entrepôt utilisé peut être différent. Les laboratoires de recherche, chercheurs, étudiants seront attirés par des entrepôts disciplinaires ou multidisciplinaires. Par ailleurs, les professionnels des SIC et ou les organisations utilisent les entrepôts disciplinaires ou multidisciplinaires, et mixtes.
Pouvons-nous chiffrer les entrepôts existants ?
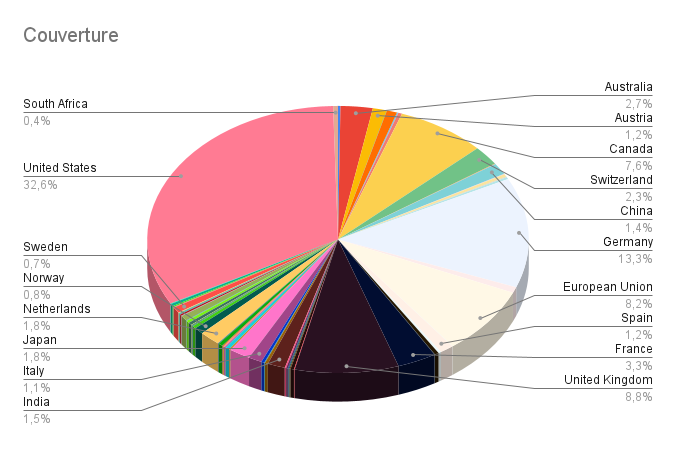
Les données statistiques de l’annuaire re3data.org [4] en date du 20/05/2021 (Fig.2) révèlent que les Etats Unis (USA) possèdent le volume le plus élevé en termes d’entrepôts de données. Ensuite l’Allemagne, la Grande Bretagne, l’Union européenne et le Canada. En ce qui concerne les pays du SUD, l’Afrique du Sud, est le pays qui est le mieux couvert en termes d’entrepôts de données. Comment le chercheur doit s’y prendre pour opérer son choix ?
Mieux choisir son entrepôt de données
Quels critères pour le choix d’un entrepôt de données ?
D’entrée de jeu, choisir un entrepôt pour héberger les données de recherche n’est pas une mince affaire, et avec l’évolution galopante des principes de la science ouverte il est nécessaire de repasser ces critères de choix au peigne fin. C’est pourquoi, il faut évoluer d’une manière graduelle, sous forme de check-list. Il faut se poser les bonnes questions, ci-dessous quelques questions qui devraient guider vos choix. :
- Est-ce que les données de recherches à disposition sont FAIR (Findable, Accessible, Interoperable, Reusable) ?
Initié en 2014 par FORCE 11, et publié en 2016 les Principes FAIR [5] sont un ensemble de résolution ayant pour but de faciliter la découverte, l’accès, l’interopérabilité et la réutilisation des données de recherche mis à disposition par les chercheurs. Cette opération d’évaluation peut être automatisée à l’aide d’outil, comme FAIR data assessment tool [6] qui permet d’évaluer le caractère « FAIR » d’un jeu de données.
- Est-ce que cet entrepôt attribue des identifiants pérennes aux ressources hébergées ?
A titre d’exemple nous avons (idHAL, DOI, URI etc.)
- Existe-t-il des métadonnées descriptives qui décrivent à la fois le support et le contenu de la donnée afin de faciliter son repérage et sa compréhension ?
Les métadonnées, descriptives obéissent à plusieurs standards, nous pouvons trouver en fonction des dispositifs : Text Encoding Initiative (TEI), Dublin Core (DC), Metadata Encoding and Transmission Standard (METS) etc.
- Existe-t-il des conditions de diffusion, de partage ou de réutilisation des données hébergées ?
L’un des ratios sur lequel vous pouvez vous appuyer, c’est la licence. Il en existe plusieurs désignés sous le nom de Creative Commons.
- L’entrepôt permet -il de citer systématiquement les jeux de données ?
Chaque donnée a un niveau de communicabilité, fonction de la politique de diffusion définie par l’auteur, l’utilisateur peut avoir accès ou non au contenu de la ressource. Mais cela ne doit en aucun cas empêcher la ressource d’être citée.
- Existe-t-il un Data Management Plan (DMP) ?
Ce processus basé sur le circuit et le cycle de vie des données, prend en compte les délais légaux de conservation, les différentes politiques de conservation, etc.
- Est-ce un entrepôt de données certifié ?
Le Coretrusteal est un organisme de certification des entrepôts de données de la recherche.
Toutefois, il existe des outils qui répondent aux questions ci-dessus et qui sont compatibles aux principes FAIR. C’est le cas de Search Repositories [7] sur le site du Coretrusteal, Repository Finder [8] de Data Cite. Et l’annuaire re3data.org. [9] que nous recommande d’utiliser Sylvie Cocaud et Pascal Aventurier en 2017 lors du séminaire de l’INRA sur « les entrepôts de données de recherche » [10].
Comment un entrepôt peut passer FAIR ?
Cette question revient assez souvent, il n’existe pas de solution miracle pour rendre un entrepôt FAIR. Tout débute par la mise en application des exigences desdits principes au sein de votre entrepôt ou la prise en compte de ces aspects dans votre stratégie projet, c’est plus une question de bonne pratique d’exploitation et d’ouverture des données
Quelques exemples d’entrepôts Européen et Africain
Zenodo [11]: est un entrepôt de l’Union européenne développé par l’Organisation Européenne pour la Recherche Nucléaire (CERN) créé en 2013, il est parfaitement interopérable avec GitHub une infrastructure américaine d’hébergement de code source. Actuellement sur cette plateforme, il est possible de charger jusqu’à 50 GB par jeu de données. Chaque jeu de données publiés possède un DOI ayant le préfix « 10.5281 » et le radical « zenodo ». Les données hébergées couvrent les sciences humaines et sociales, les sciences de la vie, et enfin les sciences de l’ingénieur. En matière de contenu, il est courant de retrouver sur zenodo des codes sources, des archives, des documents sonores, textuels, des images, des fichiers de données et enfin des vidéos. En terme de métadonnées, nous n’allons pas aborder l’ensemble, mais nous présenterons celles qui nous semblent les plus significatives à savoir : titre, auteur, date, doi, mots clés, résumé.
Nakala [12]: est une infrastructure française de recherche en sciences humaines et sociales, conçue par Huma-num en 2016. Disponible en 3 langues à savoir le français, l’espagnol et l’anglais. Les contenus pris en charge sont variés, nous avons les images, textes, données et sons. Il est possible d’affiner la recherche d’un jeu de données en fonction des critères : type, licence, année et pertinence. Les identifiants pérennes sont composés d’un préfix « 11280 » et un radical spécifique au jeu de donnée décrit. Quant au standard utilisé pour la description des métadonnées, il s’agit du Dublin Core, nous retrouvons des champs tels que : DOI, titre, date, auteur, licence, type.
Datafirst [13]: Conçu par l’université de Cape Town afin d’offrir un accès libre aux données en Open Data du gouvernement Sud-Africain, et aux gouvernements ou institutions africaines. Ce dispositif ne fournit pas suffisamment d’information sur sa politique de protection ou de conservation des données, il s’appuie sur le standard Dublin Core pour décrire l’ensemble des métadonnées qui sont hébergées au sein de celui-ci, en guise de métadonnées nous pouvons rencontrer le titre, l’identifiant pérenne, l’année, le pays de dépôt, l’éditeur, l’auteur, et la date etc.
Egypt’s Information Portal (EIP) [14]: est géré par l’Egyptian Cabinet, Information and Decision Support Center. Ce dispositif sert de vitrine au gouvernement égyptien en matière d’Open Data. Depuis quelques mois le gros des contenus de la plateforme a été migré sur les systèmes embarqués Android et IOS. Les domaines disciplinaires, comme les sciences humaines et sociales, les sciences naturelles, les sciences de la vie, les sciences de l’ingénieur sont couverts. Les métadonnées identifiées nous avons titre, éditeur, lien du fichier, résumé, et enfin date.
Evaluation du niveau de FAIR des entrepôts Zenodo, Nakala, Datafirst, EIP
Notre analyse s’appuie sur plusieurs critères évoqués au sein de cet article afin d’identifier avec précision les dispositifs les plus conformes aux principes FAIR.
Tableau 1: Analyse comparée
|
Critères FAIR |
Zenodo | Nakala | Datafirst | EIP |
| Accès libre | ||||
| Identifiant pérenne | ||||
| Métadonnées | ||||
| Licence | ||||
| Citabilité | ||||
| DMP | ||||
| Certification | ||||
| Politique de dépôt |
Cette analyse révèle que les entrepôts des deux aires géographiques semblent ne pas être totalement conformes aux exigences FAIR. D’où l’absence de certification dans la plupart des cas. Cependant, seul Data First est totalement conforme aux exigences FAIR. Pour pallier les manquements des autres entrepôts nous proposons un ensemble de stratégie à mettre en place.
En définitive, pour faciliter l’accès et la réutilisation des données de recherche, nous devons chacun apporter notre contribution ceci passe par :
- L’usage des technologies libres dans nos projets web de mise en place d’entrepôt. En guise d’exemple HTML, PHP, PYTHON, CSS, etc. ;
- Privilégier les formats libres pour nos entrepôts : TAR, XML, ODT, PDF, etc. Ils sont facilement interopérables, et reconnus par la majeure partie des terminaux de lecture ;
- Exploiter les standards ou normes connus de description des métadonnées à savoir : Dublin Core [15], TEI [16], KBart [17], METS [18], etc. ;
- Privilégier les protocoles favorisant l’archivage pérenne au sein des dispositifs en Open Access. Par exemple OAI-PMH [19];
- Rendre les serveurs de données disponibles ;
- Sensibiliser les propriétaires d’entrepôts aux bienfaits de la certification des entrepôts «Why certification » [20];
Références bibliographiques :
[1] Centre de coopération internationale en recherche agronomique pour le développement (CIRAD). 1 – Qu’est-ce qu’un entrepôt de données de recherche.(2020). https://coop-ist.cirad.fr/gerer-des-donnees/deposer-des-donnees-dans-un-entrepot/1-qu-est-ce-qu-un-entrepot-de-donnees-de-recherche
[2] PROST Hélène, SCHÖPFEL Joachim. (2019). Les entrepôts de données en sciences de l’information et de la communication (SIC). Une étude empirique. Études de communication, 52. http://journals.openedition.org/edc/8604
[3] ISO. L’Archivage électronique – Conception et exploitation d’un système informatique pour la conservation intègre de documents électroniques – Spécifications . https://www.iso.org/fr/standard/74338.html
[4] https://www.re3data.org/browse/by-country/
[5] Go-fair. FAIR Principles .(2016). https://www.go-fair.org/fair-principles/
[6] https://www.surveymonkey.com/r/fairdat
[7] Search Repositories – CoreTrustSeal. https://www.coretrustseal.org/why-certification/search-repositories/
[8] DataCite Repository Selector . https://repositoryfinder.datacite.org/
[9] Home | re3data.org . https://www.re3data.org/
[10] https://anfdonnees2017.sciencesconf.org/data/pages/Entrepots_ANFRenatis_2017_Cocaud_Aventurier_1.pdf
[11] Zenodo – Research. Shared. https://zenodo.org/
[12]Nakala . https://www.nakala.fr/
[13] DataFirst – Home . https://www.datafirst.uct.ac.za/
[14] http://www.eip.gov.eg/Default.aspx
[17] https://www.openedition.org/26973
[18] https://www.loc.gov/standards/mets/mets-home.html
[19] http://www.openarchives.org/pmh/
[20] https://www.coretrustseal.org/why-certification/
PROST Hélène, SCHÖPFEL Joachim.(2019). Les entrepôts de données en sciences de l’information et de la communication (SIC). Une étude empirique. Études de communication, 52. http://journals.openedition.org/edc/8604
COCAUD Sylvie, AVENTURIER Pascal.(2017). Les entrepôts de données de recherche. Participer à l’organisation du management des données de la recherche, gestion de contenu et documentation des données. Action Nationale de Formation organisée par les réseaux Renatis et Médici, Centre National de la Recherche Scientifique (CNRS), pp.63 . https://hal.archives-ouvertes.fr/hal-01595599
AVENTURIER Pascal, DESCONNETS Jean-Christophe.(2019). FAIRISATION des Entrepôts. Atelier JNSO 2019. IRD – Institut de Recherche pour le Développement (France) https://jnso2019.sciencesconf.org/data/pages/INTROD_1.PDF