
Data paper, data journal, matériel supplémentaire, entrepôt de données … Si les années 90 et l’essor d’Internet ont vu naître et se développer différentes initiatives et programmes politiques autour du libre accès et des principes FAIRs, les solutions d’ouverture des données de la recherche se sont mises en place petit à petit pour aboutir à une liste de possibilités offertes aux chercheurs.
Mais comment ne pas se perdre dans ce labyrinthe du partage des données de la recherche ? Et pourquoi, finalement, “prendre le temps” de les rendre publiques ? Nous tenterons de nous frayer un chemin dans le dédale de la publication et du partage des données de la recherche en prenant pour modèle la Data Publication Pyramid, et plus précisément les deuxième, troisième et quatrième niveaux …
OPEN RESEARCH DATA : UN OBJECTIF, CINQ ENJEUX !
“L’ouverture des données de la recherche (open research data) a pour objectif la diffusion libre, gratuite et universelle, via internet, des données d’origine publique ou privée. Le terme ouvert est défini comme la liberté d’utiliser, de modifier et de redistribuer librement les données” [1]. L’open data considère la science comme un bien commun dont la diffusion est d’intérêt public et général. Ce mouvement s’inscrit donc dans l’Open science [2] et l’Open knowledge [3].
Selon Laurence Dedieu et Marie-Françoise Fily, l’ouverture des données de la recherche répond à cinq enjeux majeurs [4] :
- accélérer les découvertes scientifiques, les innovations et le retour sur investissement en recherche et développement ;
- encourager la collaboration scientifique et les possibilités de recherche interdisciplinaire ;
- éviter la duplication des expériences, favoriser la réutilisation des données et minimiser le risque de perte des données ;
- assurer l’intégrité et la reproductibilité de la recherche (meilleure qualité des résultats, transparence des méthodologies) ;
- accéder librement à une masse de données ouvrant de nouveaux champs d’analyse non envisagés par le producteur des données (gain de temps et de ressources).
Nous comprenons bien là l’importance de rendre publiques les données de la recherche.
VOUS AVEZ DIS RESEARCH DATA, DATA SET, DATABASE ? AVANT TOUTE CHOSE, DE QUOI PARLONS-NOUS ?
Afin de mieux appréhender notre propos, arrêtons-nous quelques instants sur quelques définitions…
Selon l’OCDE [5], les données scientifiques sont « des enregistrements factuels (chiffres, textes, images et sons), qui sont utilisés comme sources principales pour la recherche scientifique et sont généralement reconnus par la communauté scientifique comme nécessaires pour valider des résultats de recherche. Un ensemble de données de recherche constitue une représentation systématique et partielle du sujet faisant l’objet de la recherche. Ce terme ne s’applique pas aux éléments suivants : carnets de laboratoire, analyses préliminaires et projets de documents scientifiques, programmes de travaux futurs, examens par les pairs, communications personnelles avec des collègues et objets matériels (par exemple, les échantillons de laboratoire, les souches bactériennes et les animaux de laboratoire tels que les souris). »
Le Digital Curation Center et l’Australian National Data Service apportent des définitions complémentaires. Pour le premier, une donnée est « une représentation réinterprétable de l’information dans une manière formalisée et adaptée à la communication, l’interprétation, ou le traitement » [6]. Pour le second, “fournir une définition faisant autorité des données de recherche est difficile, car toute définition est susceptible de dépendre du contexte dans lequel la question est posée ». [7]
Mais tous définissent les données de la recherche comme l’ensemble des informations collectées, observées ou créées sous une forme numérique dans le cadre d’un projet de recherche.
Les données de la recherche peuvent se regrouper de la façon suivante [8] :
- Les données d’observation : il s’agit là de données “capturées” en temps réel, habituellement uniques et donc impossibles à reproduire ;
- Les données expérimentales : autrement dit les données obtenues à partir d’équipements de laboratoire, qui sont souvent reproductibles mais parfois coûteuses ;
- Les données computationnelles ou de simulation : ce sont les données générées par des modèles informatiques ou de simulation, souvent reproductibles si le modèle est correctement documenté ;
- Les données dérivées ou compilées : par définition les données issues du traitement ou de la combinaison de données « brutes », elles sont souvent reproductibles mais coûteuses ;
- Les données de référence : elles se présentent sous forme de collections ou d’accumulations de petits jeux de données qui ont été revus par les pairs, annotés et mis à disposition.
Le jeu de données, “dataset”, rassemble les données brutes ou dérivées en un ensemble cohérent. Ces informations sont généralement numériques, textuelles, sonores et/ ou picturales. L’action de les rassembler permet leur recherche, leur récupération et leur réorganisation. Il peut être également défini comme une collection d’éléments connexes de données associées entre elles et accessibles individuellement ou de façon combinée, ou gérées comme une entité. Les jeux de données numériques sont formatés. Ils sont alors communicables, interprétables et adaptés à un traitement informatisé. Le jeu de données vient étayer les résultats d’une recherche publiés dans une revue. Il sera alors soit cité, soit déposé, soit cité et déposé.
Une base de données numérique (database) est un ensemble structuré et organisé permettant le stockage de grandes quantités d’informations afin d’en faciliter l’exploitation (ajout, mise à jour, recherche de données). D’où l’importance d’accompagner le jeu de données de métadonnées descriptives.
RENDRE PUBLIC UN JEU DE DONNÉES : PUBLIER, DÉPOSER, PUBLIER ET DÉPOSER
En tant qu’organisme de financement de la recherche, l’Union européenne détermine, à ce titre, les règles d’accès et de diffusion de l’information scientifique issue de ses fonds. Le Programme-cadre pour la recherche et le développement technologique (PCRD), appelé Horizon 2020, se caractérise par un Open Research Data Pilot des données générées au cours de recherches financées par Horizon 2020. L’objectif étant de promouvoir l’ouverture et la réutilisation des données et des métadonnées associées. Le 11 décembre 2020, le budget d’un montant de 95,5 milliards d’euros a été voté par l’Union européenne, lançant ainsi le programme Horizon Europe [9] consacré au financement de la recherche et de l’innovation jusqu’en 2027. Ce dernier s’inscrit dans la continuité du programme Horizon 2020 en mettant l’accent sur la science ouverte et l’accès aux résultats et aux données des recherches. Il se structure autour de trois piliers : Pilier I, Excellence science, Pilier II, Défis mondiaux et compétitivité industrielle européenne et Pilier III, Europe innovante. Ces piliers s’organisent autour de politiques et stratégies diverses.
Focus sur le Pilier I d’Horizon Europe : Excellence science
- Conseil Européen de la Recherche : première organisation européenne de financement pour la recherche exploratoire.
- Actions Sklodowska-Curie : financent des programmes de formation doctorale et postdoctorale et des projets de recherche collaborative.
- Infrastructures de recherche : fournissent des ressources et des services aux communautés de recherche pour mener des recherches et favoriser l’innovation dans leurs domaines. Les infrastructures de recherche contribueront également à la réalisation des 4 orientations stratégiques clés du plan stratégique Horizon Europe [10].
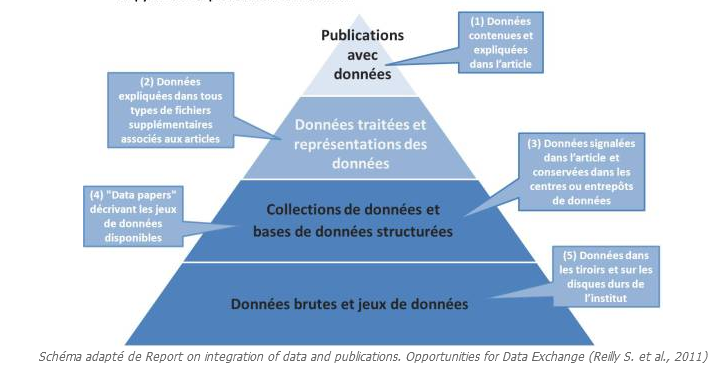
Comme nous l’avons évoqué en préambule, notre propos s’articule autour du critère de “réutilisation” des principes FAIR, nous ignorons donc délibérément le niveau concernant les données brutes stockées sur des disques durs ou “à l’abri » dans des tiroirs de laboratoire. En effet, elles ne répondent pas aux Principes FAIR et ne sont réutilisables que pour les chercheurs appartenant au laboratoire propriétaire de la recherche et, surtout, elles présentent un risque de perte d’exploitation au vu de l’éventuelle obsolescence du support et de l’outil de lecture de celui-ci. Il nous semble cependant opportun de souligner l’importance, en termes de volume, de ces données. En 2014, l’INIST [11] estime que “90% des données de la recherche sont stockées sur les disques durs locaux et potentiellement non réutilisables par d’autres”.
Avançons dans notre propos et arrêtons-nous au deuxième niveau, à savoir celui des collections de données et des bases de données structurées.
- Données publiées dans des Data Papers :
Forme récente de publication scientifique centrée sur les données de la recherche, ce type d’article se rencontre sous différentes appellations : data article, dataset paper, data notes et sous son intitulé le plus courant, le data paper. Le principe appliqué dans ce genre de production scientifique est que le contenu n’a pas pour objectif de mettre en avant un résultat, une analyse ou une conclusion.
Recette et ingrédients d’un data paper [12] :
- les métadonnées de l’article;
- le contexte de l’étude, sa conception, les procédures de production et/ ou collecte des données, les méthodes d’interprétation et de reproduction;
- la description des données;
- les notes d’usage et instructions pour la réutilisation des données.
Le but du data paper est de fournir une voie formalisée au partage des données plutôt que de tester des hypothèses ou présenter de nouvelles analyses. Ils ont pour but de rendre les données accessibles, interprétables et réutilisables.
Pour les auteurs de l’enquête “Data Journal : A Survey”, le data paper est un “article qui décrit un set de données et donne des informations sur le quoi, où, pourquoi, comment et qui de la production des données. Celui-ci contient un lien (DOI) vers le repository sur lequel est déposé le set de données et le journal qui publie l’article ne les héberge pas, ce qui garantit que même en cas d’accès restreint à l’article, le set de données reste accessible librement”.[13]
Les data papers peuvent être publiés dans des revues qui leur sont dédiées, les data journals, sous la forme d’un article examiné par les pairs [14]. Leurs jeux de données sont déposés dans des entrepôts de données, ces derniers leur attribuant un identifiant pérenne (DOI ou PID, par exemple).
Un « Data Journal » est un journal (toujours en libre accès) qui publie des articles de données. Il fournit habituellement des modèles (templates) de description des données et guide les chercheurs sur les lieux de dépôt et sur la façon de décrire et de présenter leurs données. Les Data Journals valorisent la liaison réciproque entre un article de données et le(s) jeu(x) de données (s) correspondant(s). Ils garantissent la qualité des données (processus d’examen par les pairs – Peer review) et peuvent également fournir des lignes directrices éditoriales pour l’évaluation de la qualité des données.[15]
Les avantages de la publication dans un data paper sont multiples. Les données, en étant normalisées et standardisées, sont visibles, repérables et citables par d’autres études. Ce mode de publication assure au chercheur une reconnaissance en tant qu’auteur du jeu de données en informant la communauté scientifique de l’existence et la disponibilité de ce même jeu. La méthodologie et les procédures décrites dans le data paper assurent la rigueur scientifique de l’étude.
En assurant une visibilité aux données, le data paper assure ainsi l’un des critères majeurs du principe FAIR, à savoir la réutilisation des données pour des études futures et valorise les données.
Cependant, avant de choisir la revue de publication, il convient au chercheur de vérifier l’éditeur scientifique, ses conditions d’accès (le data journal favorise l’open access, les revues hybrides non) mais également le montant des éventuels frais de publication. La visibilité du data paper dépendra également des bases de données dans lesquelles sont indexées les revues.
- Données déposées dans des entrepôts de données reconnus :
Un entrepôt de données (Data repository, digital repository) est un réservoir constitué majoritairement de données de recherche, brutes ou élaborées, qui sont décrites par des métadonnées de façon à pouvoir être retrouvées et réutilisées. Le programme cadre « Horizon 2020 » exige, sauf restrictions juridiques et éthiques, que les données issues de projets relevant de l’initiative pilote sur le libre accès aux données soient déposées dans un entrepôt accessible. Une fois déposés, les jeux de données se voient attribuer un DOI et, la plupart du temps, une licence de réutilisation. Les jeux de données sont accessibles sur l’entrepôt, éventuellement après une période d’embargo, et peuvent être réutilisés.
Mais pourquoi, me direz-vous, déposer ses jeux de données dans un entrepôt ? Outre le fait que cela soit imposé par le programme “Horizon 2020”, l’entrepôt de données permet de conserver les données dans un environnement sécurisé, de rendre les jeux de données plus visibles et citables via un identifiant pérenne. Ce dépôt permet aussi la réutilisation des données et leur reproductibilité par la communauté scientifique, ce dernier critère favorisant la validation scientifique et l’intégrité en recherche.
Il existe différents types d’entrepôts : thématique ou disciplinaire (Réseau Quetelet, par exemple, pour les sciences sociales), multidisciplinaire (Zenodo), institutionnel (Datapartoge pour l’INRAe) et spécifique d’un projet de recherche. Il est conseillé de privilégier un entrepôt de confiance, répondant aux critères de qualité exigés pour obtenir une certification [16] (format des données, qualité des métadonnées, conditions d’accès et de réutilisation, identifiant pérenne, archivage à long terme, …). Le chercheur, en tant que producteur de données et rédacteur du data paper, peut choisir lui-même l’entrepôt où déposer ses données, tout en tenant compte des recommandations de son institution ou du bailleur de fonds. Mais, si le jeu de données fait l’objet d’une publication, que ce soit dans une revue ou un data paper, le choix de l’entrepôt peut être imposé par la revue de publication, certaines d’entre elles possèdant leur propre entrepôt de données (exemple de GigaDB qui est lié à Oxford Univ. Press).
Passons maintenant au niveau supérieur et voyons ce qu’il en est des données intégrées dans les Supplementary files [17] (Matériel supplémentaire) associés à un article.
Au vu de l’augmentation significative du nombre de documents supplémentaires dans les revues scientifiques, il est possible de publier les données sous forme de fichiers supplémentaires associés à un article (article de recherche, étude de cas, etc.). Le contenu de ce matériel supplémentaire est varié. Il peut s’agir de fichiers audio, vidéo, images à haute résolution, analyses statistiques, explications méthodologiques approfondies, etc …
Ce mode de publication des données apporte plusieurs avantages. Outre le fait que les données en matériel supplémentaire soient libérées des contraintes éditoriales, les supplementary files assurent la paternité des données et le crédit aux chercheurs.
Cependant, quelques pratiques restent à revoir. En effet, le signalement des fichiers supplémentaires reste encore à standardiser et, même si l’identification des données indépendamment de l’article est possible, via notamment un DOI, elle reste rare. Et surtout, les données restent difficiles à trouver indépendamment de l’article et dans une forme peu ou pas réutilisable.
Et nous voici au sommet de notre pyramide : les données intégrées dans les revues scientifiques. Il s’agit du modèle de publication traditionnel dans lequel le chercheur traite, analyse l’ensemble des données et expose les conclusions qu’il en tire. Les données ainsi exposées sont citables, repérables et réutilisables. Cependant, les données sont difficilement repérables en dehors de la publication de l’article.
Aux côtés des données intégrées, certains éditeurs de revues demandent aux chercheurs de lier aux articles les données qui en sont la base. Elles peuvent reposer sur une politique des données [18] et dans ce cas l’auteur devra s’y conformer. Elles peuvent également imposer des entrepôts de données, en suggérer ou laisser libre choix à l’auteur. Pour exemple, là où Cahiers Agricultures n’impose pas de politiques de données, PLOS Neglected Tropical Diseases impose le choix d’un entrepôt de données public [19].
A l’issue d’un groupe de travail, le Collège Données de la Recherche conclue cependant que si “ces politiques de données sont en passe de se généraliser pour les revues en sciences, technologies et médecine”, elles “sont encore peu courantes pour les revues en sciences humaines et sociales”.
Notre propos s’achève ici. Force est de constater que le partage des données de la recherche n’est pas un long fleuve tranquille et que le chercheur doit prendre en considération plusieurs critères avant de choisir son mode de diffusion et de mise à disposition. Sans oublier que le principe de la science ouverte est de permettre la réutilisation de ces données en les rendant “aussi ouvertes que possible”…
Références:
[1] Dedieu, L., & Fily, M.-F. (2015). Rendre publics ses jeux de données. https://coop-ist.cirad.fr/content/download/5705/42112/version/5/file/CoopIST-rendre-publics-jeux-donnees-avril-2015.pdf
[2] https://www.ouvrirlascience.fr/
[4] Dedieu, L., & Fily, M.-F. (2015). Rendre publics ses jeux de données. https://coop-ist.cirad.fr/content/download/5705/42112/version/5/file/CoopIST-rendre-publics-jeux-donnees-avril-2015.pdf
[5] Principes et lignes directrices de l’OCDE pour l’accès aux données de la recherche financée sur fonds publics. (2007). http://www.oecd.org/fr/science/sci-tech/38500823.pdf
[6] “A reinterpretable representation of information in a formalized manner suitable for communication, interpretation, or processing.” – Representation Information: what is it and why is it important? | DCC
[7] “Providing an authoritative definition of research data is challenging, as any definition is likely to depend on the context in which the question is asked” ands.org.au
[8] Gaillard, R. (2014). De l’Open data à l’Open research data : Quelle(s) politique(s) pour les données de recherche ? [ENSSIB]. https://www.enssib.fr/bibliotheque-numerique/notices/64131-de-l-open-data-a-l-open-research-data-quelles-politiques-pour-les-donnees-de-recherche
[9] https://ec.europa.eu/info/research-and-innovation/funding/funding-opportunities/funding-programmes-and-open-calls/horizon-europe_en
[10] https://op.europa.eu/en/web/eu-law-and-publications/publication-detail/-/publication/3c6ffd74-8ac3-11eb-b85c-01aa75ed71a1
[11] Une introduction à la gestion et au partage des données de la recherche—Données et publications (2014). https://www.inist.fr/wp-content/uploads/donnees/co/module_Donnees_recherche_20.html
[12] Le Deuff, O. (2018). Une nouvelle rubrique pour la RFSIC : Le Data Paper. Revue française des sciences de l’information et de la communication, 15, Article 15. http://journals.openedition.org/rfsic/5275
[13] Candela, L., Castelli, D., Manghi, P., & Tani, A. (2015). Data journals : A survey. Journal of the Association for Information Science and Technology, 66(9), 1747‑1762. https://doi.org/10.1002/asi.23358
[14] Dedieu, L. (2016). Publier un data paper [Vidéo]. https://video.cirad.fr/videos/2016_03_data_paper/Laurence_Dedieu.mp4
[15] Key components of data publishing : Using current best practices to develop a reference model for data publishing – RDA/ WDS Working group on Publishing data Workflows Paper. (2015, décembre 4). RDA. https://www.rd-alliance.org/key-components-data-publishing-using-current-best-practices-develop-reference-model-data-publishin-0
[16] Application des principes TRUST transparence (Transparency), responsabilité (Responsibility), orientation vers l’utilisateur (User focus), durabilité (Sustainability) et technologie (Technology).
[17] aussi appelés : Supplemental material, Supplemental data, Auxiliary information, Supporting information, Supplementary content, Additional content …
[18] Une politique de données précise ce que la revue attend de ses auteurs en matière de gestion, d’archivage et de diffusion des données de recherche liées aux publications qu’elles éditent.
[19] https://coop-ist.cirad.fr/publier-et-diffuser/publier-dans-une-revue-en-libre-acces/6-l-acces-aux-donnees-de-recherche-associees-aux-articles