
Depuis l’avènement d’Internet, le nombre de données créées ne cesse de croître. Chaque internaute est producteur de données, chaque donnée fournit de l’information qu’il convient de conserver. Comment est né l’archivage du web français ? Qui en a la charge ? Comment les archiveurs font-ils face à ce tsunami d’informations ?
L’archivage du web mondial et le dépôt légal du web français ont fêté les 22 et 23 novembre dernier leur anniversaire. Alors qu’Internet Archive, fondation américaine pionnière en la matière, fête ses 20 ans, le dépôt légal du web français a eu 10 ans. Plusieurs initiatives ont eu lieu au cours de ces deux décennies dans différents pays notamment en Suède, en Australie et au Portugal[1]. Pour harmoniser les pratiques et unir les efforts face à un défi sans frontières, l’organisation International Internet Preservation Protocol (IIPC) a été fondée en juillet 2003 à l’initiative de la Bibliothèque Nationale de France. Son rôle est de favoriser la coopération entre les acteurs internationaux qui s’intéressent à la préservation du web. C’est en 2006 que la loi relative au droit d’auteur et aux droits voisins dans la société de l’information (dite loi DAVDSI) a rendu obligatoire le dépôt légal du web en France. Les missions, allant de la collecte à la sauvegarde, ont donc été confiées aux institutions déjà en charge du dépôt légal des autres médias, respectivement la Bibliothèque Nationale de France (BNF) et l’Institut National de l’Audiovisuel (INA). Cependant, la méthodologie de collecte du dépôt légal diffère de la méthodologie classique car il n’y a pas d’obligation de dépôt pour les sites web. Il est question d’un moissonnage de l’Internet où le patrimoine est volumineux, volatile et mouvant.
L’archivage du web sous le prisme des 5 V
V comme Volume

La fondation Internet Archive conserve plus de 25 Pétabytes de données (1015), ce qui équivaut à 510 milliards de pages ! Fin 2016, la BNF conservait 29 milliards de fichiers, pour un volume de 668 Téraoctets d’archives web avec un accroissement de 120 Téraoctets chaque année. Près de 4,5 millions de pages web sont collectées tous les ans ! Tandis que l’INA conservait 52, 3 milliards de ressources web et avait capté 389 millions de tweets qui occupent un espace de 3,95 Pétabytes ! En comparaison, la moitié du catalogue analogique de la Bibliothèque Nationale de France (ca. 6 millions de livres) équivaut à 1 Téraoctet[2]…
V comme Variété
La variété des données n’est pas en reste ! Le web est un média qui propose de multiples ressources : du texte, de l’image fixe, de l’image animée, du son, des créations telles que les web-documentaires, les infographies, les e-books, etc. Les données sont complexes et hétérogènes. L’archivage du web doit permettre de reconstituer les éléments collectés, quelles que soient les ressources.
V comme Vélocité (rapidité, flux)
En plus du volume et de la variété, les sites média, c’est-à-dire les sites qui procurent du contenu sous forme visuelle, textuelle et sonore, proposent des données volatiles et réactives. Les sites web sont des sources primaires, ce qui signifie que les producteurs d’informations les diffusent en premier lieu sur Internet. La caractéristique première d’un site web est d’être un élément dynamique, où le contenu et la mise en forme sont régulièrement mis à jour et modifiés. « Un site Web change ou disparaît tous les quatre-vingts jours en moyenne. Et avec, c’est notre culture, notre histoire, la trace de nos vies qui disparaissent. Le Web a besoin d’une mémoire », expliquait Brewster Khale dans un article du Monde intitulé « Vingt ans d’archivage du web : les coulisses d’un projet titanesque »[3].
V comme Valeur et Véracité
Les 3 V précédemment cités s’accompagnent des enjeux liés à la valeur ainsi qu’à la véracité des sites collectés. Chaque site est porteur d’informations véhiculant des valeurs, qu’elles soient financières, qualitatives ou bien symboliques. Prenons l’exemple du site de la Maison Blanche aux États-Unis qui s’est vu dévaloriser de son accès en langue espagnole dès l’installation de Donald Trump dans le bureau ovale[4]… Pour poursuivre avec l’exemple américain, il n’est plus nécessaire de rappeler à quel point la véracité des informations peut être mise en doute et donc à quel point il est primordial de la préserver.
Tous ces éléments (Volume, Variété, Vélocité, Valeur et Véracité) permettent de rapprocher l’archivage du web des projets de Big data.
Quelle gouvernance des données pour archiver le web ?
La gouvernance des données consiste en la bonne gestion du cycle de vie des données. Les organisations documentaires sont expertes en la matière mais les spécificités du numérique leur ont demandé quelques ajustements et adaptations. Passons en revue les différentes étapes de la gouvernance avec l’objectif d’archiver le web, un patrimoine évolutif et dynamique, qui est soumis au dépôt légal mais qui, nous le rappelons, n’est pas soumis à une obligation de dépôt par les producteurs de données.
Première étape : la collecte
En France, la collecte du dépôt légal du web est assurée par la BNF et l’INA depuis la promulgation de la loi DAVDSI en 2006 et son décret d’application en 2011. Ce cadre réglementaire définit le périmètre de collecte attribué à chacune des deux institutions.
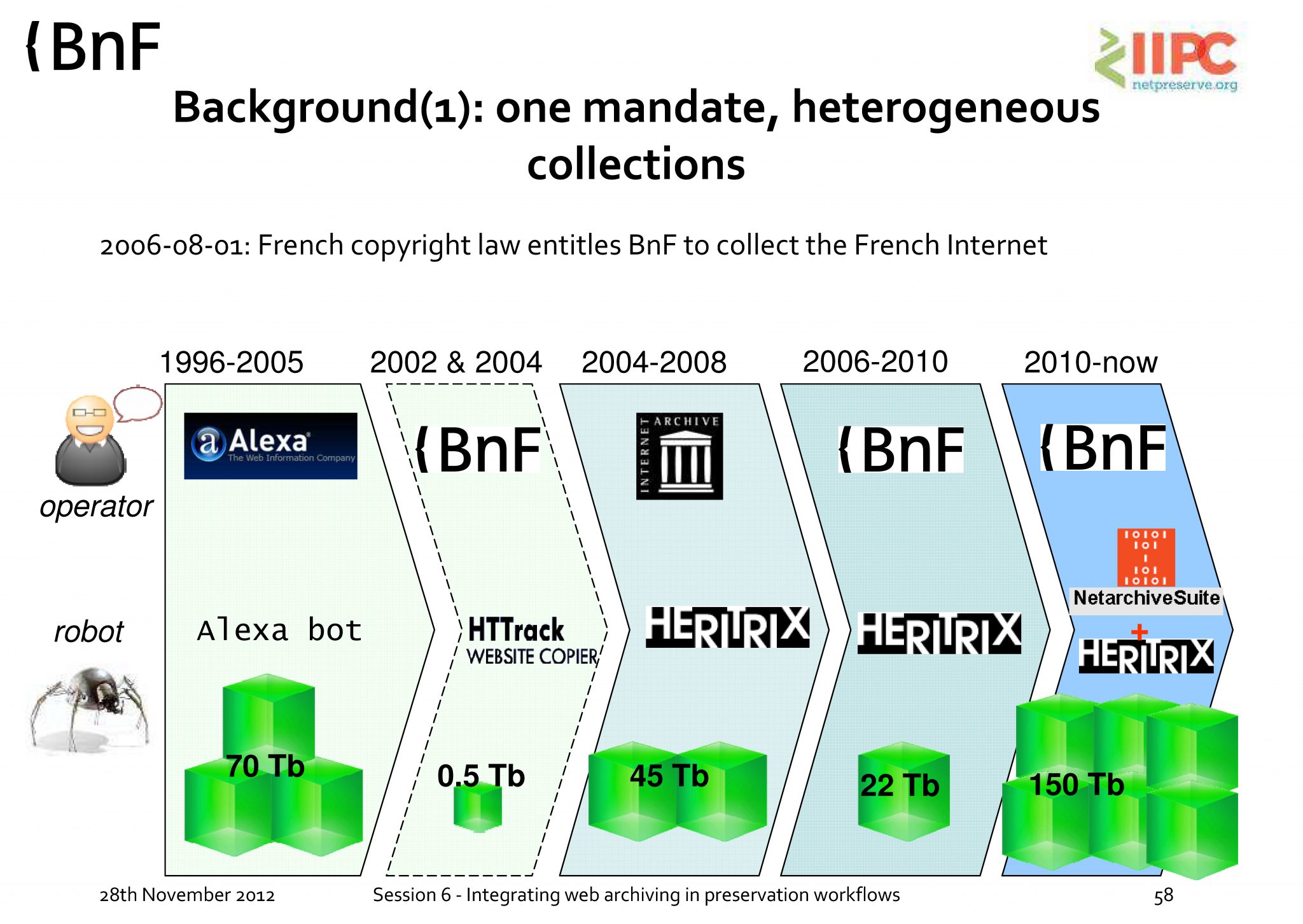
Source : http://netpreserve.org/sites/default/files/resources/CombinedPresentations.pdf (consulté le 30/03/2017)
Bien que tous les sites ne puissent pas être archivés, la BNF a pour périmètre de collecte le web français en .fr ou toutes autres extensions liées au territoire national par exemple : .re (La Réunion), .nc (Nouvelle-Calédonie), etc. mais également d’autres sites grâce à un élargissement du périmètre défini selon des thématiques ciblées. L’objectif est de constituer un échantillon représentatif du web à un moment donné mais aussi de recueillir les données associées à des événements ou à des thématiques ciblées. Pour cela, l’archivage du web est effectué via des collectes « larges » et des collectes « ciblées » dont la périodicité de moissonnage et la profondeur de recueil sont décidées par les différents départements. Une procédure de collecte d’urgence vise aussi à couvrir la collecte des sites éphémères (sites web de festival par exemple). Les outils utilisés, depuis mars 2017, sont la dernière version de NetArchive Suite[5] basé sur le crawler web Heritrix 3. Ces outils open-source améliorent la qualité et la couverture des collectes.
A partir de 2009, l’INA a pris en charge la collecte du web français du secteur de la communication audiovisuelle. Celui-ci se limite à 14000 sites mais leur moissonnage est quotidien. Il y a 4 grands axes : « Les sites web des chaînes de télé et radio ; les Web Tv et les Web Radios ; les contenus édités par les acteurs de l’audiovisuel (accès depuis les plateformes de partage audiovisuelles) ; et les sites liés aux programmes diffusés par les chaînes (émissions, séries, sites de fans…) ». Les outils de collecte sont développés en interne. La documentation concernant ces outils est très peu disponible sur le web.
Deuxième étape : Classement / Traitement / Analyse
Le traitement des données collectées intervient ensuite. L’objectif visé à cette étape est de pouvoir utiliser les données via des applications qui permettent de les modifier tout en conservant les données originelles. On procède alors à un encapsulage des données[6].

Source : http://www.bnf.fr/fr/professionnels/dlweb_boite_outils/a.dlweb_formats_fichiers.html (consulté le 30/03/2017)
A la BNF, depuis 2014, on a fait le choix du format WARC. Il signifie Web ARChive et correspond aujourd’hui à la norme ISO 28500 : 2009 pour la préservation du web. Il s’agit de l’héritier du format ARC développé par Internet Archive. Le format WARC est un format conteneur qui permet à un fichier de contenir plusieurs objets pour le stockage, la gestion et l’échange. Le WARC rend possibles « notamment l’enregistrement des entêtes de requête HTTP, l’enregistrement des métadonnées, l’attribution d’un identifiant pour chaque fichier conteneur, la gestion des doublons et des dossiers ayant migrés, la segmentation des documents. Les fichiers au format WARC sont destinés à stocker tout type de contenu numérique, qu’il soit récupéré par HTTP ou via un autre protocole. »[7]
L’INA utilise un format développé en interne, le format DAFF (Digital Archive File Format) pour l’encapsulage des données après la collecte. Comme précédemment, il y a très peu d’informations disponibles sur ce format. S’agit-il d’un format ouvert ? Il est difficile de répondre à cette question.
NOTES ————————————-
[1] Initiatives d’archivage du web :
- en Suède : http://www.kb.se/english/find/internet/websites/
- en Australie : http://pandora.nla.gov.au/
- au Portugal : http://arquivo.pt/?l=en
[2] Gabriel Siméon, « Données le vertige », [en ligne] http://www.liberation.fr/futurs/2012/12/03/donnees-le-vertige_864585 (consulté le 31/03/2017)
[3] Morgane Tual, « Vingt ans d’archivage du web : les coulisses d’un projet titanesque », [en ligne] http://www.lemonde.fr/pixels/article/2016/10/26/vingt-ans-d-archivage-du-web-un-projet-titanesque_5020433_4408996.html (consulté le 30/03/2017)
[4] Amandine Rebourg, »Donald Trump Président : le site de la Maison Blanche n’est plus disponible en espagnol » [en ligne] http://www.lci.fr/international/donald-trump-president-le-site-internet-de-la-maison-blanche-n-est-plus-disponible-en-espagnol-2023074.html (consulté le 04/06/2017)
[5] https://sbforge.org/display/NASDOC52/NetarchiveSuite+Overview
[6] Voir définition dans le glossaire.
[7] Source : http://europa-eu-audience.typepad.com/fr/2009/06/format-warc-publi{b23bcbc6564704ae5314c50cf6e55ef99bc09de32ef3fcb54190da321a083ca4}C3{b23bcbc6564704ae5314c50cf6e55ef99bc09de32ef3fcb54190da321a083ca4}A9e-en-tant-que-norme-iso-pour-la-pr{b23bcbc6564704ae5314c50cf6e55ef99bc09de32ef3fcb54190da321a083ca4}C3{b23bcbc6564704ae5314c50cf6e55ef99bc09de32ef3fcb54190da321a083ca4}A9servation-du-web.html (consulté le 31/03/2017)
Poster un Commentaire
Vous devez vous connecter pour publier un commentaire.