
L’emploi d’identifiants uniques et pérennisables dans le temps représente un enjeu fort pour le développement de la science ouverte et des principes FAIR[1].
Aujourd’hui, une très grande quantité de production scientifique sont disponibles ou signalées sur le web. Faciliter la recherche et le partage d’information en exploitant des identifiants qualifiés apparait rapidement comme une nécessité. Mais pour garantir la disponibilité libre et indépendante sur le long terme des informations scientifiques, les formats et la gouvernance de ces identifiants sont également à questionner.
A- Étiqueter le monde
1- Des identifiants globalement uniques
Un identifiant pérenne est une chaine de caractère alphanumérique. En général ce code n’est pas signifiant en lui même. Il est souvent abrégé par l’acronyme PID pour Persistant IDentifier en anglais. Son rôle est de garantir l’identification d’une ressource ou d’une personne quelle que soit sa nature. Les objets peuvent être des publications, des jeux de données brutes ou traitées, des images, des sons, des concepts dans un thésaurus… Les entités référencées, pour leur part, concernent aussi bien des personnes physiques que des institutions ou des entreprises : des chercheurs, des universités, des organismes financeurs, ou encore des personnages historiques.
Le rôle des identifiants est à la fois de désambiguïser les termes et de gérer les homonymies. Par exemple, dans un univers numérique, il est important de pouvoir différencier les notions attachées au mot «opéra». Le bâtiment et l’œuvre scénique auront chacun un code différent pour les repérer. De la même manière, Jacques Martin, l’illustrateur de bande dessinée (ISNI 0000 0001 2033 0240) n’aura pas la même suite chiffrée que l’animateur télé (ISNI 0000 0000 7359 228X) pour assurer la distinction. Il s’agit de réaliser une association unique entre un code et une entité de sens. Pour être complètement performante, l’association devra être globalement unique. Son unicité devra se vérifier dans un environnement le plus large possible, être détachée de tout système et partagée avec la communauté utilisatrice.
L’objectif premier des identifiants pérennes est de faciliter la recherche d’information, et leur importance est souligné dès la première exigence du premier principe FAIR : F1- Attribuer des identifiants uniques et pérennes aux données.
Ce type identifiant existe déjà depuis plusieurs années pour des objets physique comme le livre avec l’ISBN (International Standard Book Number) introduit en 1970 pour qualifier de manière unique chaque édition de chaque livre publié. Dans le monde de l’édition, l’ISSN (International Standard Serial Number), dont la norme ISO a été créée en 1975 pour identifier les publications en série, est un autre exemple de PID.
2- Localiser sur le long terme
Avec le développement du numérique et plus particulièrement avec l’essor du web, l’identification univoque et durable des données, au sens large du terme, s’est adaptée pour répondre aux spécificités de ce nouvel environnement. Ainsi, Les identifiants pérennes ont une syntaxe commune qui est basée sur la spécification des URI (Uniform Ressource Identifier) du W3C[2]. Cette syntaxe est composée de trois parties :
- le protocole dans lequel l’identifiant est attribué (par ex. http:,DOI:, ARK:, etc.)
- un préfixe qui permet de désigner l’autorité nommante qui a attribué l’identifiant au sein de ce système. Les préfixes ont besoin d’être unique au niveau mondial et sont donc gérés par des institutions internationales. Par exemple l’IANA [3] (Internet Assigned Numbers Authority) a attribué le préfixe 12148 pour identifier la BNF (Bibliothèque National de France) dans le système ARK (Archival Resource Key).
- un suffixe, c’est-à-dire une chaîne de caractères qui identifie la ressource de manière unique, au sein de ce système et pour cette autorité. Par exemple : doi:10.1045/january2005-fox
Avec internet, il est également intéressant de pouvoir localiser une ressource et d’avoir un texte actionnable pour pouvoir y accéder. Ainsi, l’identifiant est souvent associé à une adresse web. Avec la volubilité du numérique, la question de l’accès sur le long terme vient s’ajouter à la problématique de la localisation. En effet, le système d’adressage par URL (Uniform Resource Locator) lie le document à son emplacement physique sur un serveur connecté à internet. Si ce document est déplacé ou le serveur modifié, il devient impossible de retrouver le document. Ce problème est souvent matérialisé par l’erreur 404, code renvoyé par un serveur pour indiquer qu’aucune ressource n’a été trouvée à l’adresse demandée. Ainsi pour garantir la disponibilité d’une ressource, identifiée de façon univoque, les identifiants pérennes se basent sur une gestion active des liens au travers d’un résolveur. L’objectif est de faire correspondre au nom de la ressource son adresse réelle de manière la plus durable possible. Le résolveur peut être interne à l’institution qui donne les noms, ou externe et géré par une autorité indépendante.
Pour rendre actionnable un identifiant, il sera précédé de l’adresse d’un résolveur. Son rôle est de redirigé l’internaute vers la ressource, quelque soit son emplacement sur le web. Si on prend le résolveur d’identifiant de type HANDLE de la Bibliothèque du Congrès à Washington et la ressource de l’exemple précédent on peut construire l’adresse suivante, alors que la ressource n’a aucun lien avec l’institution du résolveur :
Par exemple : http://hdl.loc.gov/doi:10.1045/january2005-fox
Ainsi, les identifiants pérennes permettent à la fois de rendre facile à trouver une ressource et de garantir son accessibilité. Ils participent donc aux principes FAIR.
3- Une prolifération des identifiants
Le système PID s’est largement développé. Aujourd’hui de nombreuses plateformes et organismes attribuent des identifiants aux données hébergées et à leurs auteurs. Concernant les contributeurs, il existent une multitudes d’identifiants locaux fournis par les éditeurs commerciaux comme par exemple Clarivate avec l’identifiant ResearcherID ou Elsevier avec Scopus Author ID. Les sites de réseaux sociaux tel que ResearchGate ou Academia.edu délivrent aussi leur propre identifiant. Les plateformes d’archives ouvertes peuvent proposer la création d’un identifiant local, par exemple idHAL pour l’archive ouverte HAL, ou arXiv author ID pour l’archive ouverte Arxiv.
A cela s’ajoute des identifiants globaux comme l’ISNI (International Standard Name Identifier) défini par une norme ISO ou l’ORCID (Open Researcher and Contributor ID) dédié spécifiquement aux membres de la communauté scientifique.
Les objets, publications ou jeux de données, ont aussi leur propre système comme HANDLE, DOI, ARK…

Si le système des identifiants pérennes répond aux principes FAIR, leur prolifération tend à limiter les avantages. Pour répondre aux objectifs de la science ouverte et garantir la l’accessibilité sur le long terme des informations scientifiques, il est nécessaire de s’assurer que les identifiants s’appuient sur des protocoles standards, libres, ouverts et soutenus par la communauté scientifique. Il est donc important de prendre en considération l’ensemble du système pour s’assurer de répondre, à tous les niveaux, aux différentes prérogatives énoncées par les principes FAIR.
B- Fédérer les initiatives pour relier les données
1- Un engagement politique
Un plan national pour la science ouverte a été initié en France suite au discours du 4 juillet 2018, de Frédérique Vidal, Ministre de l’Enseignement supérieur, de la Recherche et de l’Innovation. Ce plan divisé en 3 grandes axes vise en autre à favoriser le développement des principes FAIR. À ce titre la France s’est notamment engagée dans diverses entreprises pour s’assurer que les identifiants pérennes répondent à ces principes. L’objectif général est de soutenir l’utilisation de standards et de protocoles ouverts et partagés par la communauté scientifique (cf. R4, A1 et A2 des principes FAIR).
Ainsi, le comité pour la science ouverte participe au consortium ORCID, regroupant de nombreux acteurs scientifiques au niveau international pour promouvoir et co-gérer le développement de ce système. Cet identifiant est ainsi indépendant et gratuit pour les chercheurs. En plus d’identifier de manière unique n’importe quel auteur scientifique qui en fait la demande, l’ORCID associe des métadonnées décrivant le profil du chercheur. Présenté sous la forme d’une page web (ORCID record), ce CV permet au chercheur de gérer lui même ses informations et de les lier à ces différents autres identifiants. Ce numéro est interconnecté avec la plupart des plateformes comme Web Of Science (WoS), Zenodo, Figshare. Il est reconnu, voire exigé, par de nombreux acteurs de la publication scientifique et permet ainsi d’associer les travaux à leur auteur : soumission d’article, demande de financement, évaluation, publication…
Pour les objets, l’Inist-CNRS (Institut National de l’Information Scientifique et Technique du Centre National de la Recherche Scientifique) s’est associé à l’organisme DataCite pour devenir l’agence d’attribution des DOI pour la France. DataCite est lui même lié à l’IDF (International DOI Foundation) qui est une organisation à but non lucrative. L’appui d’un consortium comme DataCite permet de maintenir un résolveur commun à un grand nombre d’institution. L’attribution d’un DOI demande la mise en place d’un contrat via le portail OPIDor [4]. L’identifiant est gratuit pour les chercheurs car c’est l’organisme ou l’institution de recherche qui souscrit un abonnement. Le DOI fournit un accès stable et durable à la ressource quelle que soit son emplacement sur le web. Il est aussi associé à un fichier de données dont le schéma est libre et construit par la communauté. Le schéma est consultable en ligne [5]. L’ensemble répond à la norme ISO 26324:2012 garantissant sa solidité et sa pérennité.
L’usage d’identifiants pérennes est un pilier du web des données liées. Le choix du système doit en plus répondre aux principes FAIR pour garantir l’accessibilité et l’interopérabilité nécessaire pour la science ouverte.
2- Organiser les correspondances
Un identifiant unique et durable dans un système libre et ouvert ne suffit pas forcément. En effet, aujourd’hui de nombreux systèmes coexistent, rendant l’idée d’unicité globale quelque peu caduque. Cette multiplicité s’explique par des objectifs et des besoins différents. Si certain identifiants semblent proches, en réalité ils se distinguent notamment par les métadonnées associées. Les différents schémas permettent ainsi d’avoir plus au moins de finesse selon les besoins. C’est le cas, par exemple, entre les identifiants du RNSR (Répertoire National des Structures de Recherche) et ceux d’AuréHAL (Accès Unifié aux Référentiels HAL). De même, ORCID est exclusivement destiné à l’identification des auteurs et contributeurs des domaines de l’enseignement supérieur et de la recherche alors que l’ISNI représente l’identité publique d’une personne de façon plus général dans le domaine de la création intellectuelle. De son côté, l’ABES (Agence Bibliographique de l’Enseignement Supérieur) a développé son identifiant l’IDRef permettant par exemple de qualifier tous les auteurs de thèse au nom du dépôt légal. Mais l’ORCID comme IDRef sont étroitement lié à l’ISNI. L’ABES ou la BNF assure alors un rôle d’alignement au niveau international pour tenter de faire correspondre tous ces identifiant au travers de projet comme le VIAF (Virtual International Authority File : Fichier d’autorité international virtuel) ou des plateforme comme Wikidata. L’ORCID propose aussi de lien d’autres identifiants pour favoriser l’interopérabilité.
3- Relier toutes les données
L’utilisation généralisée des PID de toutes sortes permet donc d’identifier et de localiser un grand nombres de données sur le web. L’usage de ces identifiants dans les métadonnées permet alors de relier toutes ces informations dans un vaste réseau. En répondant à l’exigence d’emploi de métadonnées avec des attributs selon les principes FAIR, il est alors possible de relier un auteur à ses travaux ou à son institution, de faire correspondre les données et la publication qui les exploitent. Les métadonnées liées favorise la réutilisation des informations tout en garantissant la paternité et la provenance.
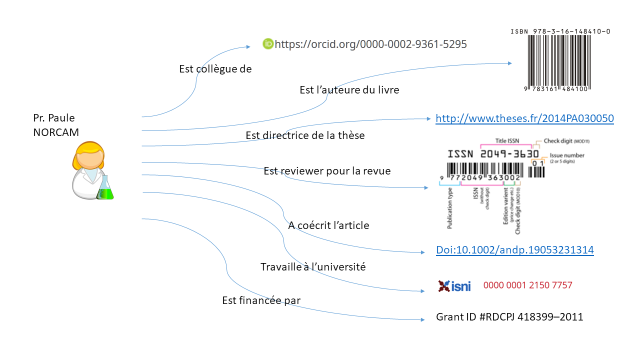
Les identifiants pérennes, en participant à un système global, augmentent la visibilité sur les web aussi bien des chercheurs et des institutions que des travaux scientifiques. L’identification d’une ressource, en étant unique, induit sa répétition à chaque utilisation, renforçant sa présence. De même, les identifiants liés facilitent la recherche d’information que ce soit par le principe même d’une identification univoque mais aussi par les rebonds permis. D’une publication, je peux retrouver l’ensemble des travaux d’un chercheur, ou l’ensemble des domaines d’une institution, ou encore l’ensemble des articles liés à une revue …
Les principes FAIR sont un ensemble de recommandations pour gérer les données de la recherche visant à les rendre faciles à trouver, accessibles, interopérables et réutilisables aussi bien par l’homme que par la machine. Le principe d’identifiant persistant est la pierre angulaire du déploiement de la science ouverte. Aujourd’hui, et surtout demain, des millions d’objets scientifiques (publications, données et autres objets numériques), produits par autant de chercheurs, affiliés à leur tour à des centaines de milliers d’organisations, peuvent être reliés grâce à des systèmes d’identifiants pérennes ouvert et alignés. Ce vaste réseau d’information favorise alors la diffusion, la découverte et le partage des données scientifiques, éléments fondamentaux de l’innovation.
Notes
[1] Énoncé des différents principes FAIR : https://www.go-fair.org/fair-principles/
[2] RFC 3986 : http://www.ietf.org/rfc/rfc3986.txt
[3] Internet Assigned Numbers Authority. La liste des préfixes enregistrés est accessible en ligne : http://www.iana.org/assignments/uri-schemes.html
[4] Portail mis en place par l’Inist-CNRS : https://opidor.fr/identifier/
[5] Schéma de métadonnées DataCite : https://schema.datacite.org/
A lire :
Sur le site de DORAnum :
- les ressources consacrées aux principes FAIR : https://doranum.fr/enjeux-benefices/principes-fair/
- les ressources consacrées aux identifiants pérennes : https://doranum.fr/identifiants-perennes-pid/
Les différentes ressources proposées sur le site du comité pour la science ouverte : https://www.ouvrirlascience.fr/category/ressources/
Le site de l’ABES consacré au réseaux IDref/ORCID : https://abes.fr/reseaux-idref-orcid/le-reseau/
Le site de la BNF présentant les identifiants internationaux : https://www.bnf.fr/fr/identifiants-internationaux
Vade-mecum Identifiants pérennes pour les ressources numériques : https://www.culture.gouv.fr/Sites-thematiques/Innovation-numerique/Donnees-publiques/Identifiants-perennes-pour-les-ressources-numeriques
Projet de PID Graph du consortium Freya : https://www.project-freya.eu/en/pid-graph/the-pid-graph
Le site wikidata : https://www.wikidata.org